-
友情链接:
又一位英伟达“杀手”亮相:性能是H100数倍,成本仅1/10,支持万亿参数模型
- 发布日期:2024-09-02 03:22 点击次数:90

8月27日消息,在近日召开的Hot Chips 2024大会上,美国AI芯片初创公司SambaNova首次详细介绍了其新推出的全球首款面向万亿参数规模的人工智能(AI)模型的AI芯片系统——基于可重构数据流单元 (RDU) 的 AI 芯片 SN40L。
据介绍,基于SambaNova 的 SN40L 的8芯片系统,可以为 5 万亿参数模型提供支持,单个系统节点上的序列长度可达 256k+。对比英伟的H100芯片,SN40L不仅推理性能达到了H100的3.1倍,在训练性能也达到了H100的2倍,总拥有成本更是仅有其1/10。

SambaNova SN40L基于台积电5nm制程工艺,拥有1020亿个晶体管(英伟达H100为800亿个晶体管),1040个自研的“Cerulean”架构的RDU计算核心,整体的算力达638TFLOPS(BF16),虽然这个算力不算太高,但是关键在于SN40L还拥有三层数据流存储器,包括:520MB的片上SRAM内存(远高于此前Groq推出的号称推理速度是英伟达GPU的10倍、功耗仅1/10的LPU所集成的230MB SRAM),集成的64GB的HBM内存,1.5TB的外部大容量内存。这也使得其能够支持万亿参数规模的大模型的训练和推理。
SambaNova在推出基于8个SN40L芯片系统的同时,还推出了16个芯片的系统,将可获得8GB片内SRAM、1TB HBM和24TB外部DDR内存,使得片上SRAM和集成的HBM内存之间的带宽高达25.5TB/s,HBM和外部DDR内存之间的带宽可达1600GB/s。高带宽将会带来明显的低延时的优势,比如运行Llama 3.1 8B模型,延时低于0.01s。

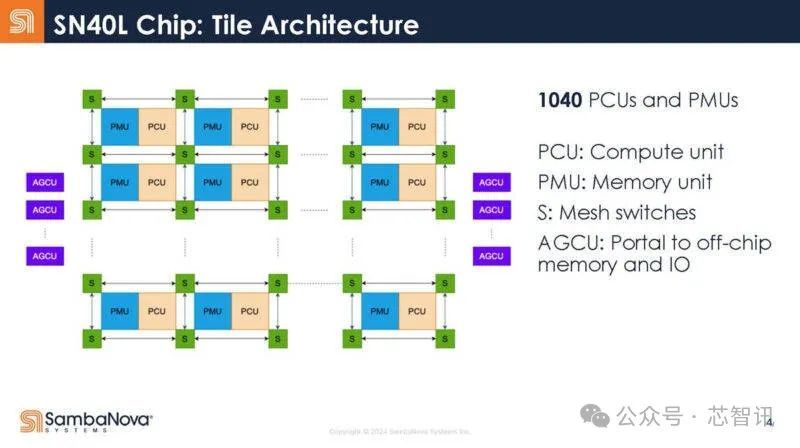
下图是SambaNova SN40L的内部结构,包括:计算单元(PCU)、存储单元(PMU)、网状开关(S)、片外存储器和IO(AGCU)。
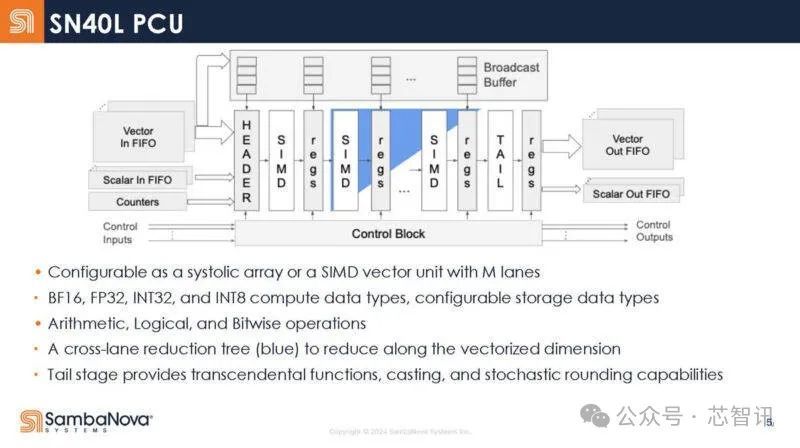
SN40L 内部的计算单元(PCU)的内部架构,它具有一系列静态阶段,而不是传统的获取/解码等执行单元。PCU可以作为流媒体单元(从左到右的数据)运行,蓝色是交叉车道减少树。在矩阵计算操作中,它可以用作收缩阵列。支持BF16、FP32、INT32、INT8等数据类型。
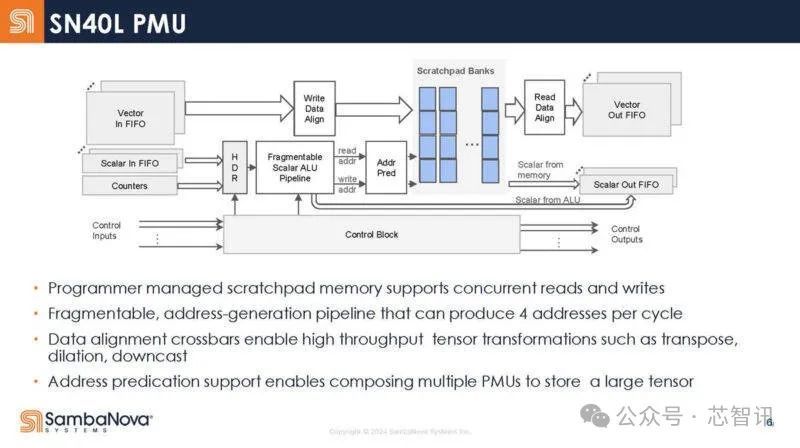
下图是SN40L 的高级存储单元框架图。这些是可编程管理的暂存区,而不是传统的缓存。
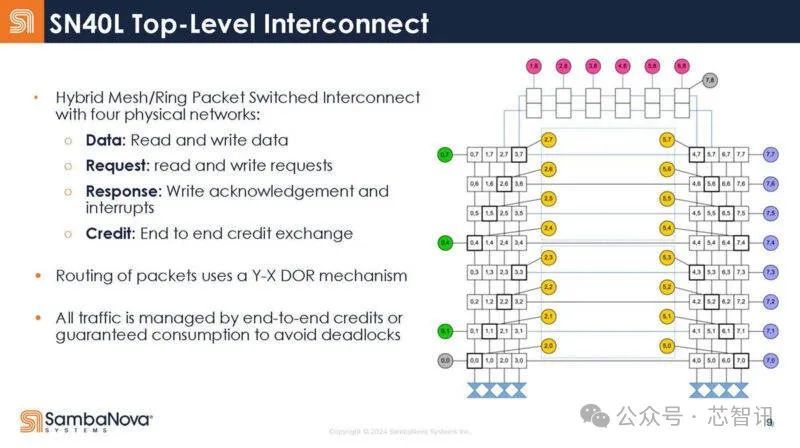
SN40L 的网状网络拥有三种物理网络,包括矢量网络、标量网络和控制网络。
AGCU单元用于访问片外存储器(HBM和DDR ),而PCU用于访问片内SRAM暂存区。
下图是SN40L 的顶层互联结构:
SN40L 的关键核心在于其可重构数据流架构,可重构数据流架构使其能够通过编译器映射优化各个神经网络层和内核的资源分配。
下面是一个例子,说明Softmax是如何被编译器捕获,然后映射到硬件的。
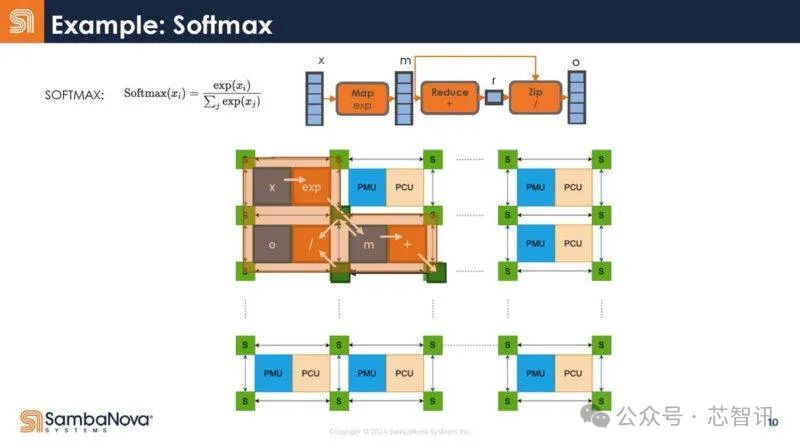
可以看到,将它映射到大语言模型(LLM)和生成式AI的Transformer模型,下面是映射。在解码器内部,有许多不同的操作。
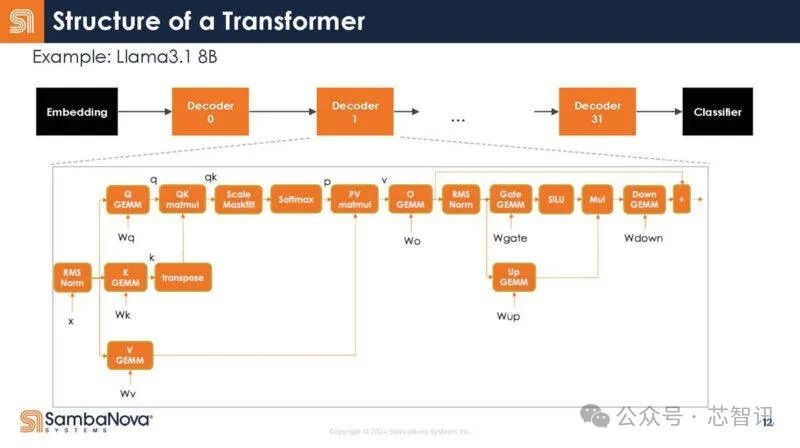
下图是解码器放大图。每个方框内都是一个操作符。同时,通常可以运行多个操作符,并把数据保存在芯片上以便重用。
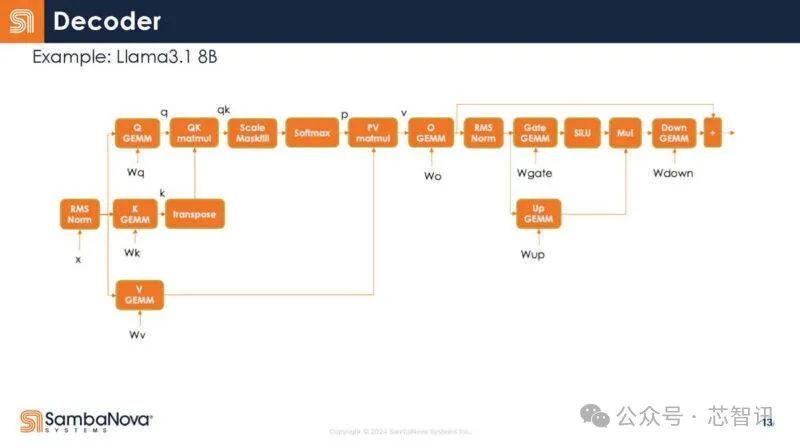
以下是SambaNova对运算符如何在GPU上融合的猜测,不过他们也指出这可能不准确。
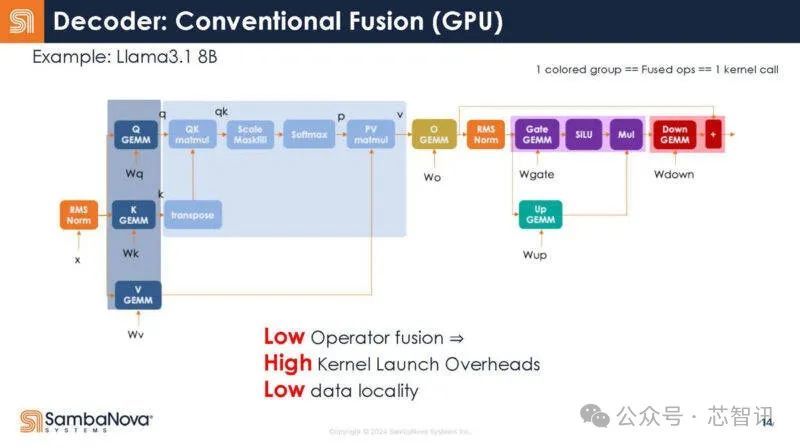
在RDU中,整个解码器是一个内核调用。编译器负责这种映射。
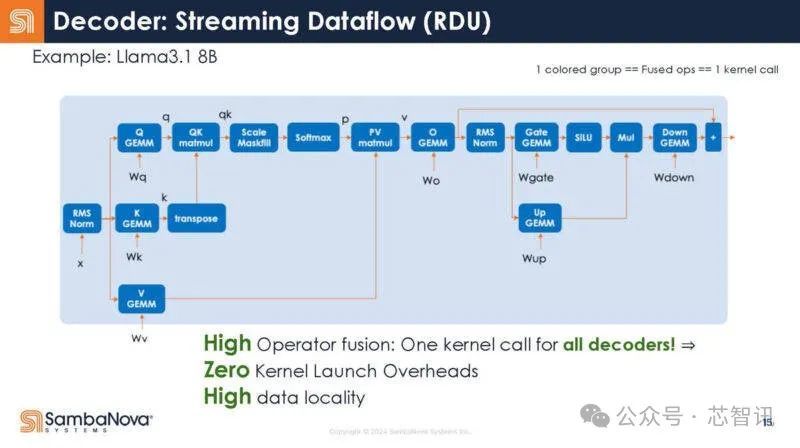
解码器作为RDU上的单个内核。

回到Transformer的结构,下图展示了解码器的不同功能。可以看到,每个函数调用都有启动开销。
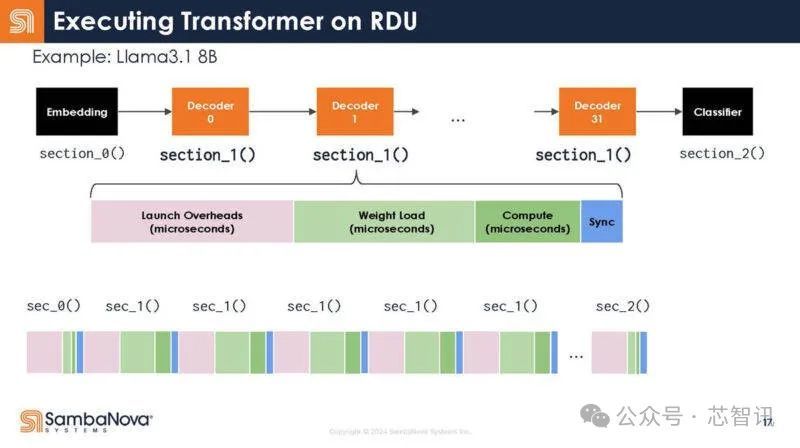
不是32个调用,而是写成一个调用。
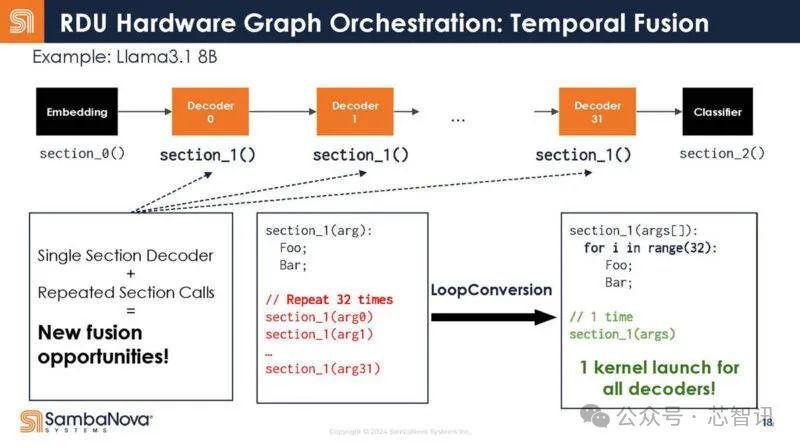
换句话说,这意味着调用开销减少了,因为只有一个调用,而不是多个调用。结果,增加了芯片对数据做有用工作的时间。
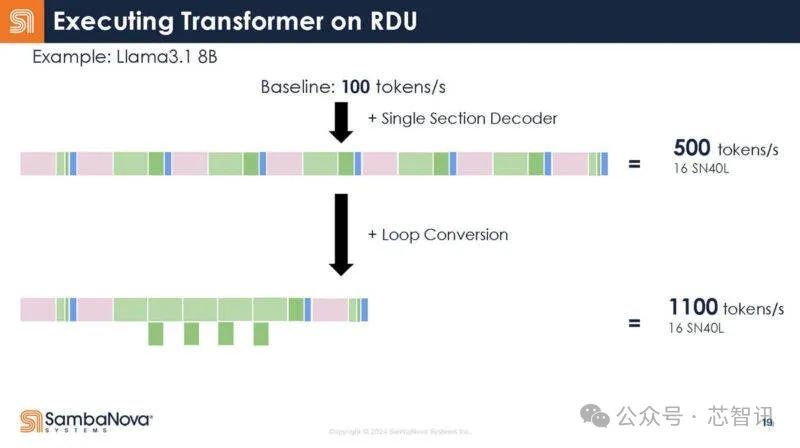
SambaNova 首席执行官兼创始人 Rodrigo Liang 表示:“借助数据流,你可以不断改进这些模型的映射,因为它是完全可重构的。因此,随着软件的改进,你获得的收益不是增量的,而是相当可观的,无论是在效率方面还是在性能方面。”
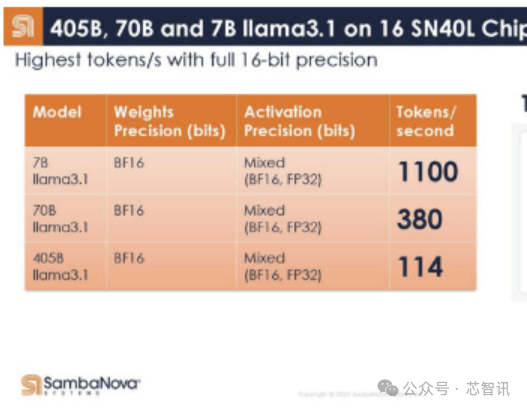
下面是SambaNova的16个SN40L芯片系统在Llama3.1 405B/70B/7B上的表现,在Llama 3.1 7B模型下,以完全的16bit精度运行,其每秒的Token生成数竟然高达1100个。这比此前Groq推出的基于LPU(号称推理速度是英伟达GPU的10倍,功耗仅1/10)的服务器系统在Llama 3 8B上的最快基准测试结果每秒生成800个Token还要快。即使是在Llama3.1 405B模型上,以完全的16bit精度运行,16个SN40L芯片的系统每秒Token生成数也能够高达114个。而在Llama 3.1 7B模型下,其每秒的Token生成数更是高达1100个。由于内存容量限制,与其最接近的竞争对手需要数百块芯片来运行每个模型的单个实例,因为 GPU 提供的总吞吐量和内存容量相对较低。
SN40L在Llama 3.1 70B模型上进行批量推理和吞吐量缩放表现,随着批量大小的变化,吞吐量接近理想规模。
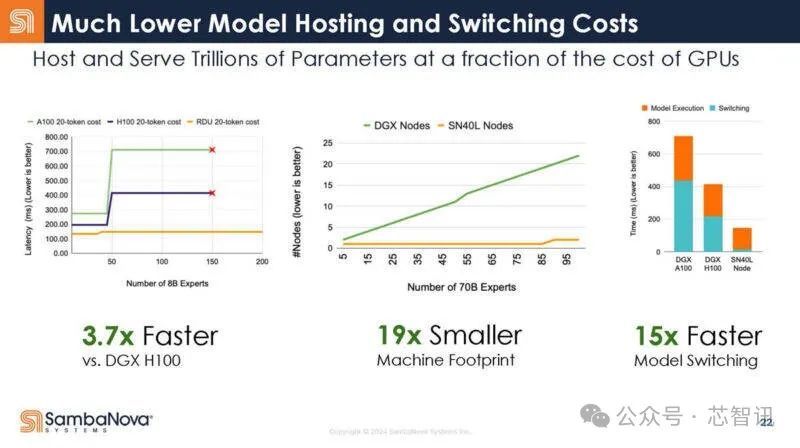
据SambaNova 介绍,基于8个SN40L芯片的标准AI服务器系统在运行80亿参数的AI大模型时,速度达到了基于8张英伟达H100加速卡的DGX H100系统的3.7倍(每生成20个Token所耗费的时间),而整个系统所占用的空间也只有DGX H100的1/19,模型切换时间也仅有DGX H100系统的1/15。
在芯片推理性能方面,SN40L达到了英伟达H100的3.1倍;在训练性能方面,SN40L也达到了英伟达H100的2倍。
总结来说,SambaNova 可以在8个SN40L芯片的系统上运行数百个大模型(在16个SN40L芯片的系统上可以同时运行多达 1000 个 Llama 3 7B大模型),同时还能够保持很快的响应速度,拥有完全精度。更为关键的是,其总拥有成本比竞争对手低 10 倍(虽然未明确是哪款竞品芯片,但从前面的对比来看,应该说的是H100)。
“SN40L的速度展现了Dataflow的魅力,它加速了 SN40L 芯片上的数据移动,最大限度地减少了延迟,并最大限度地提高了处理吞吐量。它比 GPU 更胜一筹——结果就是即时 AI,”SambaNova Systems 联合创始人、斯坦福大学知名计算机科学家 Kunle Olukotun 表示。
值得一提的是,在基于SN40L芯片的系统之上,SambaNova 还构建了自己的软件堆栈,其中包括今年2月28日首次发布的拥有1万亿参数的Samba-1 模型,也称为 Samba-CoE(专家组合),其使得企业能够组合使用多个模型,也可以单独使用,并根据公司数据对模型进行微调和训练。
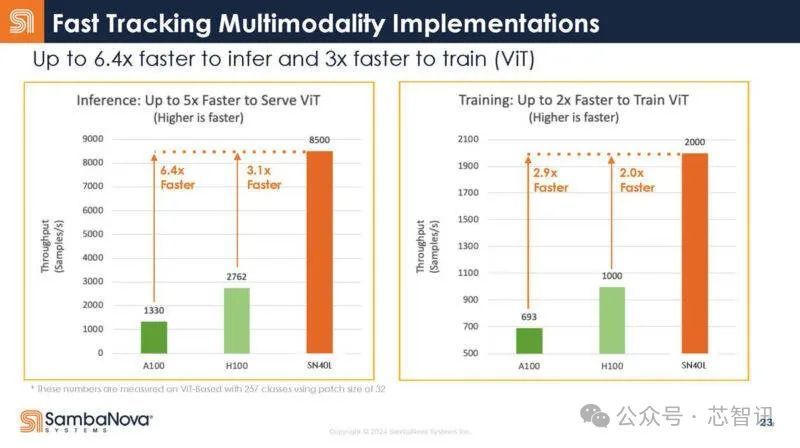
在芯智讯看来,SN40L相比目前的一些AI芯片来说,拥有着显著的优势,比如其可重构的数据流架构,可以调整硬件来满足各类工作负载要求,使得其可以很好的处理图像、视频及文本等不同的数据类型,适合多模态AI应用。但是,相对于英伟达的GPU可以灵活的处理各种模型来说,SN40L在灵活性上还是要略逊一筹,因为相关模型必须要经过专门的调整才能在其上面运行。而且,英伟达强大的CDUA生态对于其来说也是一大挑战。
不过,在AI模型参数越来越大,所需的芯片数量和资金成本越来越高的背景之下,SN40L在性能和成本上的优势,以及可以轻松实现对于万亿参数大模型的支持,因此也有着与英伟达直接竞争的机会。或许正因为如此,SambaNova也获得了资本的青睐,目前已经累计获得了超过10亿美元的融资。
编辑:芯智讯-浪客剑
相关资讯
-
天津向海乐活节开幕 打造文旅盛宴
- 关于蓝狮在线 2024-06-14
- 中新网天津6月8日电 (王顺琦)6月8日,2024年天津夏季向海乐活节在国家海洋博物馆开幕,宣布了200多场精彩纷呈的夏季活动,集文化、旅游、体育与学术于一体,旨在为市民和游客打造一个充满活力的暑期体验。 天津向海乐活节启动仪式。王顺琦 摄...
-
Mate 60降价800元、Pura 70降价1000元:就等华为发布Mate 70了!
- 关于蓝狮在线 2024-08-25
- 很显然这些降价的措施,第一是为了迎接开学季,第二则是为Mate 70上市做准备。 快科技8月16日消息,对于现在的华为手机来说,已经在努力给接下来新机上市扫清道路了,所以大家看到了Mate 60系列和Pura 70系列陆续降价。 随着8月1...
-
三只小狗过水渠视频一夜爆火:我可能是那小黄狗,却还不如它
- 关于蓝狮在线 2024-06-08
- 作者:洞见muye 怕什么前途无望,进一寸有一寸的欢喜。 最近看到一个视频,只有短短十几秒,我却聚精会神地看了好几遍。 三只小狗过水渠,水渠比较长,里面蓄满了水。 每隔一段距离就设有一道窄窄的矮墙,形成一个一个小河坝。 三只小狗过水渠,各显...